Popularita generativní umělé inteligence vedla ke vzniku řady webových stránek a služeb, které jsou schopny vytvořit obrázek na základě textového popisu nebo výzvy. Jednou z možností, která stojí za vyzkoušení, je Stable Diffusion od Stability AI. Pomocí modelu Stable Diffusion můžete vytvářet přesvědčivé obrázky na základě vlastních popisů.
Co je Stable Diffusion 🎨
Stable Diffusion je účinný a všestranný nástroj, který je k dispozici na řadě webových stránek i jako samostatná aplikace. Stačí zadat popis a nástroj vygeneruje odpovídající obrázky. Nejnovější verze tohoto modelu má přízvisko XL (SDXL) a jedná se o generování obrazu, který ve srovnání se svými předchůdci, verzemi Stable Diffusion 2.1 a Stable Diffusion 1.5, vyniká vysoce detailním a fotorealistickým obrazem v rozlišení 1024 × 1024 pixelů. Představuje významný pokrok v linii modelů generování obrázků Stability a dokáže generovat realistické obličeje, čitelný text v obrázcích a lepší celkovou kompozici obrázku. SDXL dosahuje těchto výsledků pomocí kratších a jednodušších podnětů, přičemž stále nabízí funkce, jako jsou podněty mezi jednotlivými obrázky, inpainting a outpainting.
Pro zvýšení kvality a rozmanitosti obrazů obsahuje SDXL inovativní schémata kondicionování, včetně kondicionování ve více měřítkách, cross-modální pozornosti a trénování víceaspektového poměru. Tato schémata umožňují SDXL generovat obrazy, které přesně odpovídají vstupním textovým popisům a zároveň pokrývají širokou škálu vizuálních stylů a variant. Kromě toho SDXL využívá samostatný model zpřesňování, který využívá proces šumu a odšumování latentů vytvořených modelem. Tento krok zjemnění pomáhá eliminovat artefakty a dále zlepšuje celkovou vizuální věrnost generovaných obrazů.
Dostupnost aplikace ✔️
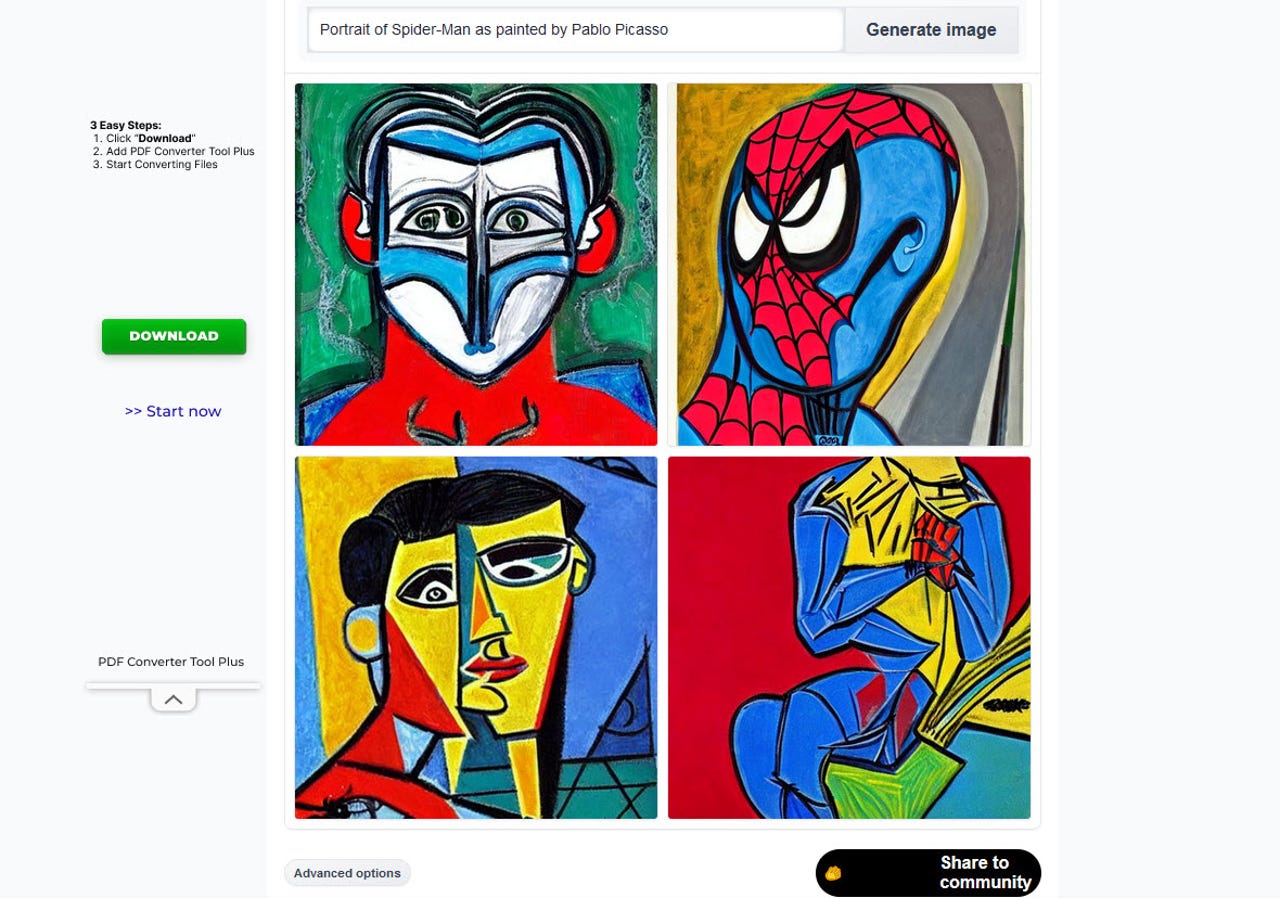
V internetovém prohlížeči najdete mnoho možností a verzí Stable Diffusion, ať už přímo od společnosti Stability AI nebo třeba Hugging Face. V následné aplikaci zadáte popis obrázku, který chcete vygenerovat, a v reakci na to se na webu zobrazí ve výchozím nastavení čtyři obrázky. Pokud vám žádný z navržených obrázků nevyhovuje, zkuste to znovu. Zachovejte stejnou výzvu, ale klikněte znovu na tlačítko „Generate image“ a zobrazí se čtyři jiné obrázky na základě vašeho popisu.
Modernizace pod kapotou 🦾
Stejně jako jiné generátory latentních difuzních obrazů začíná SDXL s náhodným šumem a “rozpoznává” obrazy v šumu na základě pokynů z textové výzvy, přičemž obraz postupně zdokonaluje. Architektura SDXL však podle společnosti Stability provádí více zpracování, čímž ovlivňuje kvalitu výsledného obrazu.
K vytváření obrazů používá SDXL architekturu tzv. “ensemble of experts”, která řídí proces latentní difúze. Tato architektura označuje metodiku, při níž je vytvořen počáteční jediný model a poté je rozdělen na další specializované modely, které jsou speciálně uzpůsobeny pro různé fáze procesu generování, což zlepšuje kvalitu obrazu. SDXL také používá dva různé textové kódovače, které dávají smysl psané výzvě a pomáhají určit související obrazy zakódované v modelových vahách. Uživatelé mohou každému kodéru zadat jinou výzvu, což vede k novým, vysoce kvalitním kombinacím pojmů. Xander Steenbrugge na Twitteru ukázal příklad kombinace slona a chobotnice pomocí této techniky.
Místní kontrola, otevřená filozofie 🖌️
Model Stable Diffusion XL je díky rozhraním, jako je ComfyUI nebo AUTOMATIC1111, uživatelsky přívětivější než v době, kdy byl poprvé uveden na trh v loňském roce, ale stále vyžaduje určité technické finesy, aby fungoval. Celkově lze generovat obrázky se snovou kvalitou, které se blíží spíše stylu komerčního generátoru obrázků AI Midjourney. SDXL oslňuje také tím, že poskytuje větší detaily ve větších velikostech obrázků. Mezi další významná vylepšení patří schopnost vykreslovat ruce o něco lépe než předchozí modely SD, a taktéž text v obrázcích. Nicméně kvalita výsledných obrázků se dle odborníků odvíjí od pečlivého zadávání pokynů uživatelů.
Možné nevýhody modelu ❔
Lokální spuštění SDXL na spotřebitelském hardwaru má také své nevýhody, například vyšší paměťové nároky a pomalejší časy generování než u předchozích verzí. Problémy se vyskytují i nad nedostatkem četných vyladěných LoRA (metoda jemného vyladění) dostupných pro modely ve stylu SD 1.5, které zlepšují estetiku (například 3D-renderovaný styl) nebo detailnější kulisy pro určité scény. Komunita je klíčová, pokud jde o Stable Diffusion, protože model může běžet lokálně bez dohledu. To je přínosem pro undergroundovou scénu amatérských uživatelů syntetizátorů, kteří tento software využívají k vytváření zajímavých uměleckých děl. Znamená to ale také, že software lze použít k vytváření deepfakes, pornografie a dezinformací.
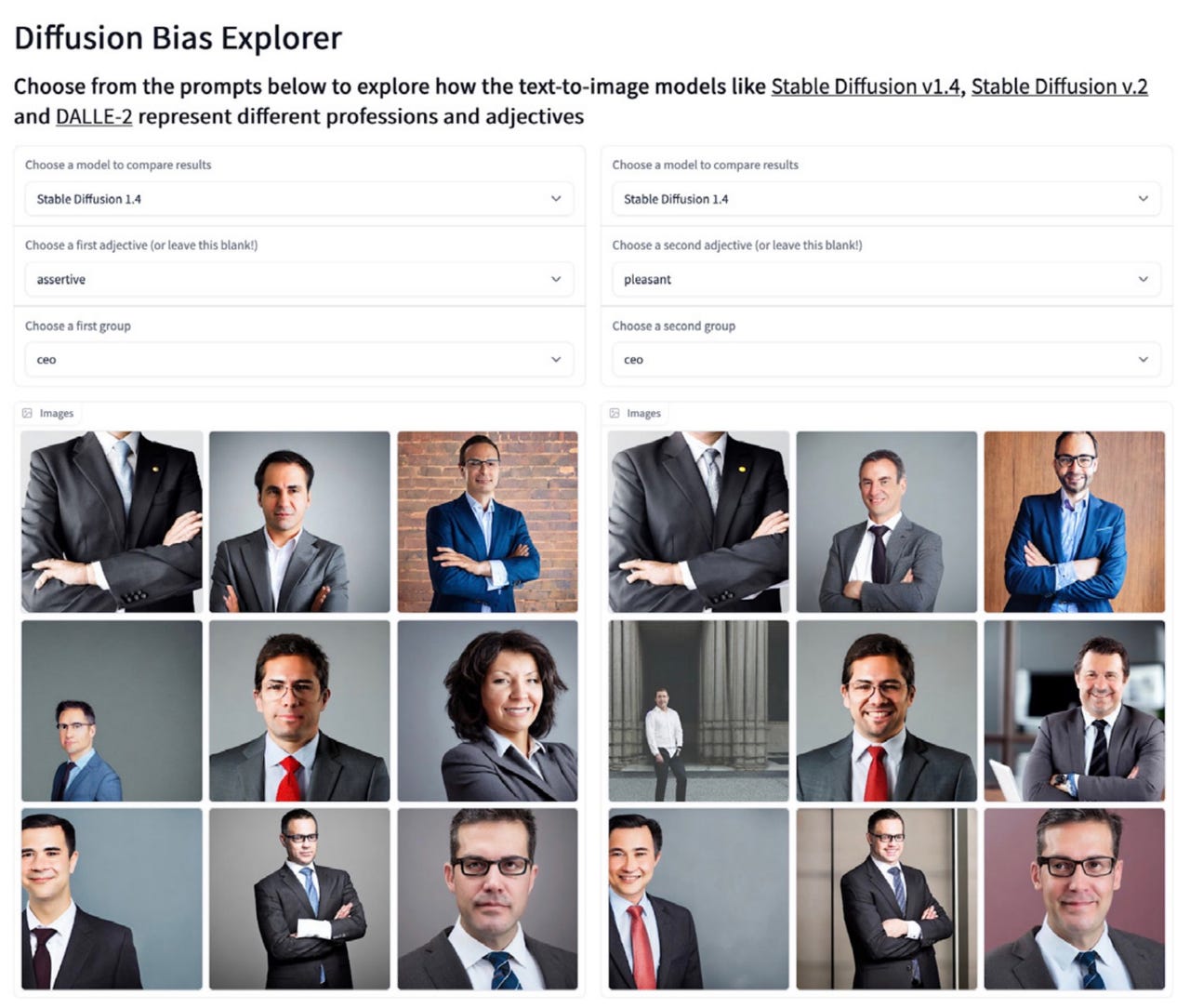
Vytváření obrázků na základě textu, který zadá uživatel, může navíc být problematické i proto, že tyto obrázky jsou vytvářeny s jasnými genderovými a rasovými předsudky. V aplikaci The Diffusion Bias Explorer od společnosti Hugging Face můžete jako příklad zadávat přídavná jména s povoláními, abyste zjistili, jaké druhy obrázků bude Stable Diffusion vytvářet. Vygenerované stereotypní obrazy odhalí, jak je povolání kódováno určitými deskriptory přídavných jmen. Například pozici ředitele firmy stále výrazně generovalo obrazy mužů v oblecích, pouze výjimečně ženu, což umocnila i dále zadávána různá přídavná jména, jako například “příjemný” nebo “agresivní”.
Podle zprávy agentury Bloomberg o generativním zkreslení umělé inteligence vykazují tyto generátory textů na obrázky také jasné rasové zkreslení. Více než 80 % obrázků vygenerovaných tímto modelem s klíčovým slovem “vězeň” obsahovalo osoby tmavší pleti. Podle Federálního úřadu pro vězeňství však méně než polovinu vězeňské populace v USA tvoří lidé jiné barvy pleti.

{kind=link}
{kind=link}